Agents are found at the highest level of abstraction. These usually refer to an organizational unit in your company or to a particularly large knowledge package. In the Agent Hub in the Genow application, these are arranged horizontally. At the Agent level, there are multiple settings to optimise the data pipeline. Additionally, there are process fit features which can also be configured at this level.
Agent settings
Make use of Agent settings to optimise your Agent.
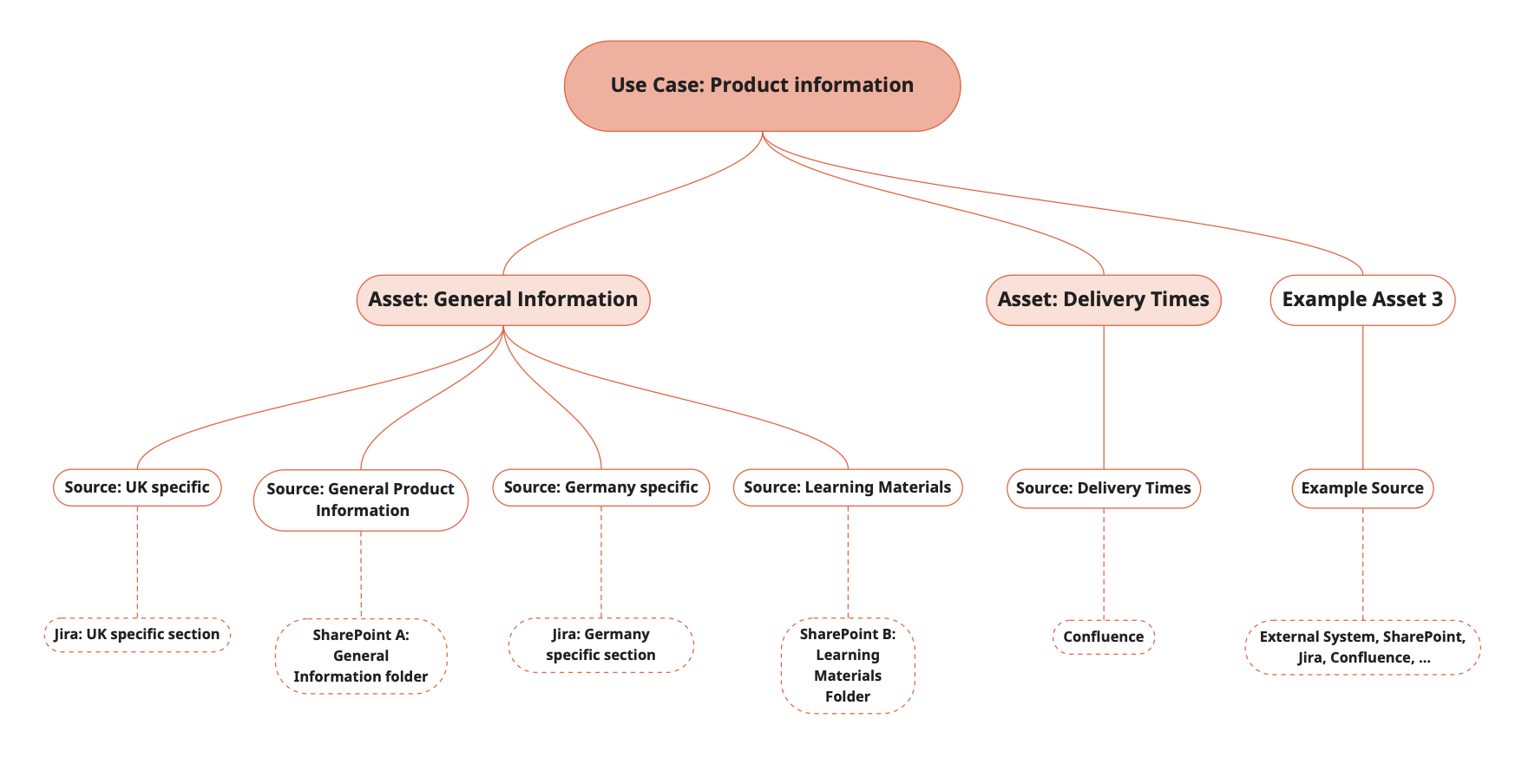
Various knowledge packages, so-called Knowledge Assets, can be created for each Agent. These are shown as rectangles in the Genow user interface after an Agent has been selected. User questions are always answered based solely on the knowledge and documents assigned to the selected knowledge assets. In most cases, end users ask questions about all selectable assets. A large number of assets can reduce clarity, but ensures that a subdivision into different knowledge bases becomes apparent. Having a high number of assets increases the cost per request (AI usage costs). It is up to you to define a good middle ground for your Agent. Most Agents have 1-4 assets.
Knowledge assets consist of several knowledge sources, i.e., smaller knowledge packages. At the cloud or storage level, knowledge sources can be folders in which files and documents are stored, or the documents themselves. For every knowledge asset, there must be at least one knowledge source!A Knowledge Source is the most direct connection to your company data and the most fundamental level in the knowledge structure of the Genow platform. Think of a Knowledge Source as a precise signpost: it points exactly to a specific location where information is stored, for example, a specific SharePoint folder, a page in Confluence, or a particular Jira project.Two crucial processes take place at this level
1
Synchronization (Sync)
This is where you manually trigger a synchronization. This process loads all current information from the source (e.g., the SharePoint folder) into the Genow platform, making it findable in queries.
2
Permission Assignment
At the Knowledge Source level, you define which users or user groups are allowed to access the data connected here.
Why you can create multiple sources and assign them to an asset? Generally, this allows for extremely flexible and granular control over your data and access permissions.
Imagine you have an Asset named “International Sales Guidelines.” The information for this asset is located in different places with different access rights. You would create three Knowledge Sources for this:Knowledge Source 1: A SharePoint folder with general sales documents. All sales employees are granted permission to access this.Knowledge Source 2: A folder with contracts and price lists for Germany only. Only the “Sales DE” user group is granted permission to access this.Knowledge Source 3: A folder with contracts and price lists for the UK only. Only the “Sales UK” user group is granted permission to access this.
The Result: All sales employees see the same “International Sales Guidelines” Asset in the Genow platform. However, when an employee from Germany makes a query, the system searches the general documents (Source 1) and the German documents (Source 2) for them. A colleague from the UK making the same query will get results from the general (Source 1) and the British documents (Source 3). This ensures that each user only sees the information that is relevant and approved for them, even though the knowledge package appears the same to everyone.
Why does it also make sense to keep the number of sources low? You can, of course, also select all your relevant directories, folders or documents and assign them to one source and one asset. This sometimes makes the synchronisation and management easier. It can make sense to create multiple sources if you are dealing with a complex topic with many separate sub-topics or complex user authorization concepts. Web searches are also managed at the knowledge source level.
A Sync (Synchronization) refers to the process by which the Genow platform deliberately retrieves data from the connected Knowledge Sources and updates its internal database.
Changes in external sources, such as editing or adding documents in SharePoint, are not transmitted to the platform in real-time, however an automatic sync (i.e. daily, once a week, …) can be configured.
The sync is the necessary mechanism to capture these modifications and reflect them within the platform. Initiating a sync ensures that all new or modified information is indexed and made available for search queries.
This process guarantees the timeliness and accuracy of the data provided by the platform. At the same time, there is no need for duplicate data.
The synchronization process is divided into two phases. First, a one-time configuration is required where a knowledge source is set up by assigning it to an Asset and defining the specific content to be included (e.g., files, folders).
After this initial setup, the recurring execution is a simple, efficient action: you only need to select the pre-configured source and trigger the sync to update the data, without needing to re-define the contents each time. Only new and updated data and documents are sychronized.
User permissions are granted based on customizable roles. This allows for high flexibility.
We distinguish between standard roles for Agent admins and users, who should be able to see (and manage in case you are an admin) all knowledge sources assigned to the Agent, and custom roles, which grant access to a specific set of knowledge sources.
Standard roles can be exported from the Agent overview in the admin panel, custom roles have to be created by Genow.
One example for different enduser groups:
For example, there is general information, as well as specific information intended for a dedicated subgroup of users.
This results in the creation of two knowledge sources: general knowledge & specific knowledge and two authorization groups using custom roles: Access to general knowledge & access to specific knowledge.
Two assets can be created that are displayed depending on the authorization or one asset that looks the same for each user but contains different data depending on the user.
We differentiate between four main access roles:
Platform admin: manages the platform and user permissions (standard role).
Agent admin: manages the Agent (standard role).
Basic user: read permissions for general Agent knowledge and all knowledge sources of the Agent (standard role).
Regional or knowledge-specific user (Optional): access to specific knowledge and therefore to a specific knowledge source.